
Tabla de Contenidos#
- 1 Embeddings
- 2 El contexto en los LLMs basados en transformer**
- 3 Contexto autorreferencial y programabilidad en los LLMs**_
- Referencias
Los modelos de IA generativa, especialmente los Modelos de Lenguaje Grande (LLMs) como GPT y sus sucesores, se han convertido en una fuerza clave en el avance de la inteligencia artificial. Aunque estos modelos han ganado prominencia por sus capacidades en el procesamiento del lenguaje natural (PLN)—incluyendo tareas como análisis de sentimientos, traducción automática y generación de contenido—sus aplicaciones se extienden más allá del ámbito del PLN [11].
Uno de los objetivos clave de este artículo es explorar las características y la arquitectura específicas de los modelos de IA generativa que los convierten en una tecnología fundamental para el desarrollo de Aplicaciones de Aprendizaje Inteligente. Esta exploración sirve como parte de una investigación más amplia sobre las capacidades, limitaciones y aplicaciones potenciales de estos modelos. Aunque el campo en crecimiento de la IA ofrece opciones para entrenar y ajustar modelos (fine-tuning), gracias a iniciativas de código abierto como Llama 2 y plataformas como OpenAssistant, este artículo toma un enfoque diferente. Buscamos entender cómo las funcionalidades existentes de los modelos disponibles pueden utilizarse eficazmente para desarrollar Aplicaciones de Aprendizaje Inteligente sin requerir modificaciones extensas.
Al examinar componentes críticos como los embeddings y la capacidad del modelo para entender el contexto, este artículo pretende proporcionar una comprensión matizada que pueda guiar el desarrollo de tecnología educativa y abrir nuevas vías para la innovación.
1 Embeddings#
En el corazón de los LLMs se encuentra el concepto de “embedding”. En el PLN, los embeddings sirven para transformar entidades lingüísticas—ya sean palabras, frases o documentos enteros—en vectores numéricos de dimensiones fijas. Mikolov et al. introdujeron el modelo Word2Vec, un método popular para generar embeddings de palabras, que ha sido fundamental en el desarrollo de embeddings en los LLMs [12]. Esta transformación es pivotal ya que permite representar los datos textuales de una manera que es tanto computacionalmente eficiente como semánticamente rica. A través del proceso de embedding, los LLMs están equipados para discernir patrones y relaciones intrincadas en el lenguaje.
1.2 Aplicaciones prácticas de los Embeddings#
Los LLMs utilizan embeddings para una miríada de tareas. Desde análisis de sentimientos y traducción automática hasta la generación de contenido, las capacidades de los LLMs son vastas. La naturaleza numérica inherente de los embeddings facilita operaciones que pueden deducir relaciones, establecer analogías y discernir matices en el lenguaje. En el ámbito de la traducción automática, los embeddings han sido instrumentales para identificar términos equivalentes entre idiomas, asegurando que las traducciones mantengan su significado y precisión [13].
Un ejemplo notable de la aplicación práctica de los embeddings es proporcionado por ChatPDF.com, un sistema llave en mano que permite la incrustación de PDFs enteros, abarcando cientos de páginas. Este sistema permite una interfaz de chat con el documento, ofreciendo un enfoque innovador para la interacción con documentos. ChatPDF.com también proporciona una API para desarrolladores, facilitando la integración de este modelo amigable con embeddings en diversas aplicaciones [14].

2 El contexto en los LLMs basados en transformer**#
En el ámbito de los LLMs, particularmente modelos como GPT-4 y BERT basados en la arquitectura transformer, el término “contexto” denota la información circundante inmediata que el modelo aprovecha para generar una respuesta [15, 16]. Para GPT-4, este contexto se deriva del texto precedente en una conversación o documento. Dicho contexto es indispensable ya que proporciona al modelo información sobre el tema en curso, el tono y el estilo de la conversación, y cualquier instrucción o restricción específica.
Un mecanismo esencial que permite esta comprensión contextual es el mecanismo de “atención”. En las arquitecturas transformer, la atención permite al modelo ponderar diferentes partes del texto de entrada de manera diferente. Esto significa que al generar una respuesta, el modelo no trata todas las palabras o tokens en el contexto por igual. En su lugar, “presta atención” más a ciertas partes que son más relevantes para la consulta o el prompt en cuestión. Por ejemplo, si la conversación es sobre el cambio climático, palabras como “emisiones”, “carbono” y “temperatura” podrían recibir pesos de atención más altos. Este mecanismo de atención funciona en tándem con el contexto para producir respuestas más precisas y contextualmente apropiadas.
Sin embargo, la comprensión del contexto en los LLMs se extiende más allá del texto precedente inmediato. Dado los vastos conjuntos de datos en los que estos modelos se entrenan, poseen una comprensión integral de una multitud de temas. Cuando se presenta con un contexto específico, el modelo profundiza en esta extensa base de conocimientos, enfocándose en los segmentos relevantes para elaborar una respuesta apropiada.
2.1 Contexto como entrenamiento ad hoc#
La propuesta de utilizar el contexto como una forma de entrenamiento ad hoc presenta un enfoque novedoso para interactuar con los LLMs. Howard y Ruder introdujeron la idea de ajustar (fine-tuning) modelos preentrenados para tareas específicas, lo cual está relacionado de alguna manera con la idea de entrenamiento ad hoc [17].
Al proporcionar a un LLM un contexto distinto o un conjunto de instrucciones, los usuarios tienen la capacidad de “guiar” las respuestas del modelo en tiempo real. Este método de proporcionar orientación contextual actúa efectivamente como entrenamiento instantáneo, moldeando el comportamiento del modelo sin necesidad de alterar su arquitectura fundamental o sus pesos.
En nuestra exploración del papel del contexto en los modelos de lenguaje, presentamos dos figuras contrastantes para resaltar la diferencia que el contexto puede hacer en las respuestas generadas por un chatbot.
La Fig. 3 describe un escenario donde se le pide a un chatbot, entrenado con datos hasta 2021, que escriba un ensayo de dos párrafos sobre la Copa Mundial Femenina de la FIFA 2023 desde la perspectiva de una niña de 10 años. En este caso, el chatbot carece del contexto específico del evento y, por lo tanto, produce una respuesta basada en su entrenamiento pre-2021, careciendo de detalles específicos sobre el evento.
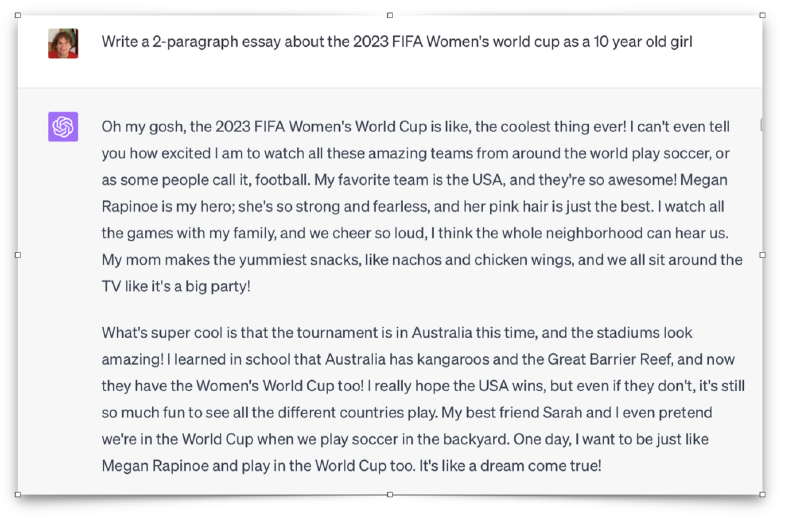
Por otro lado, la Fig. 4 muestra el mismo chatbot, pero esta vez se le proporciona contexto en forma de un fragmento de texto de la página de Wikipedia sobre la Copa Mundial Femenina de la FIFA 2023. Cuando se le hace la misma pregunta, el chatbot es capaz de generar una respuesta detallada, discutiendo el evento deportivo, los resultados, los países participantes y las personas involucradas, como si hubiera sido entrenado específicamente con esa información.
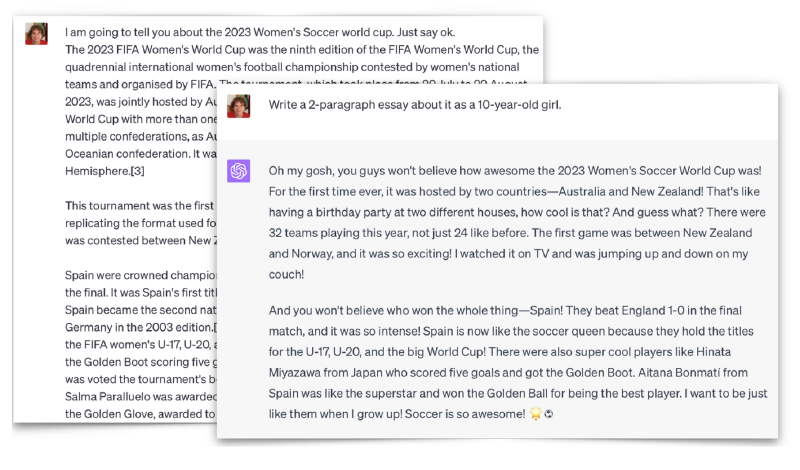
3 Contexto autorreferencial y programabilidad en los LLMs**_#
Un aspecto a menudo pasado por alto del contexto en los LLMs es la naturaleza autorreferencial de sus respuestas. A medida que un LLM genera una respuesta, esa salida se convierte en parte del contexto en curso para las interacciones subsiguientes. Esta característica dinámica permite una forma única de programabilidad y seguimiento de instrucciones en los LLMs.
Un aspecto del contexto en los Modelos de Aprendizaje de Lenguaje (LLMs) avanzados como GPT-4 y GPT-3.5 que merece una atención más cercana es la naturaleza autorreferencial de sus respuestas generadas. Aunque los modelos anteriores de la serie GPT tienen cierta capacidad para usar el contexto dentro de una sola interacción, esta capacidad se ha mejorado significativamente en versiones más recientes. Los LLMs avanzados pueden incorporar su propio texto generado en el contexto para futuras interacciones como se representa en la Fig 5., lo que significa que a medida que el modelo genera una respuesta, ese contenido recién generado no solo sirve como respuesta a una consulta; también se convierte en parte del contexto en evolución que informa las respuestas subsiguientes.
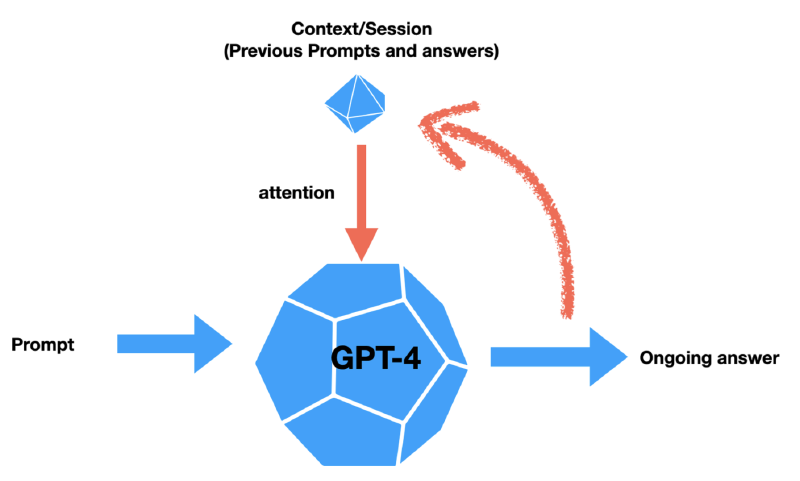
Esta característica introduce un nivel de actualización dinámica del contexto, permitiendo que el modelo siga instrucciones o realice tareas de una manera más matizada. Por ejemplo, si se le pide a un LLM avanzado como GPT-4 o GPT-3.5 que genere una receta y luego cree una lista de compras basada en esa receta, el modelo puede usar los ingredientes listados en su propia receta generada como contexto para compilar la lista de compras. Esto no solo muestra la capacidad del modelo para entender y mantener el contexto, sino que también destaca su capacidad para ser “programable” dentro del alcance de una sola interacción. Esta actualización de contexto autorreferencial hace que los LLMs avanzados sean herramientas versátiles para tareas e interacciones más complejas y de múltiples pasos.
Para ilustrar esto en la Fig 6, le pedimos a GPT-4 que generara una receta para espaguetis a la boloñesa y luego creara una lista de compras basada en esa receta. El modelo primero listó los ingredientes y los pasos para el plato y luego usó esta información para compilar una lista de compras. Esto muestra que el modelo puede usar su propio texto generado como contexto para una tarea subsiguiente dentro de la misma interacción.
Este ejemplo destaca una característica sencilla pero importante: la capacidad del modelo para actualizar su contexto dinámicamente. La lista de compras no es solo una salida separada; está directamente relacionada con la receta que el modelo proporcionó. Esto demuestra que los modelos de lenguaje pueden seguir instrucciones de su propio texto generado, permitiendo interacciones más matizadas y conscientes del contexto.

En un entorno educativo, el contexto autorreferencial puede aprovecharse para permitir que un chatbot revise, califique o proporcione retroalimentación sobre ejercicios de estudiantes. Típicamente, cuando se presenta con el texto de un ejercicio y la solución de un estudiante, tanto GPT-3.5 como GPT-4 tienden a rendir mal en la calificación y en ofrecer retroalimentación. Sin embargo, el rendimiento mejora significativamente cuando se le instruye al chatbot que primero resuelva el problema por sí mismo, luego compare la solución del estudiante con su propia solución generada y finalmente proporcione una calificación y retroalimentación. Los resultados usando este enfoque son notablemente mejores.
prompt = f"""
Determine if the student's solution is correct or not.
Question:
I'm building a solar power installation and I need \\
help working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost \\
me a flat $100k per year, and an additional $10 / square \\
foot
What is the total cost for the first year of operations
as a function of the number of square feet.
Student's Solution:
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
"""
response = get_completion(prompt)
print(response)
El código que mostramos arriba presenta un ejemplo de prompt pidiendo al chatbot que determine si la solución de un estudiante es correcta o no. Los resultados serán pobres usando este enfoque. Pero en el siguiente fragmento de código podemos ver cómo instruir cuidadosamente en el prompt para resolver primero el problema y luego considerar la solución del estudiante, los resultados serán mucho mejores (Fuente OpenAI Cookbook[18]).
prompt = f"""
Your task is to determine if the student's solution \\
is correct or not.
To solve the problem do the following:
- First, work out your own solution to the problem.
- Then compare your solution to the student's solution \\
and evaluate if the student's solution is correct or not.
Don't decide if the student's solution is correct until
you have done the problem yourself.
Use the following format:
Question:
---
question here
---
Student's solution:
---
student's solution here
---
Actual solution:
---
steps to work out the solution and your solution here
---
Is the student's solution the same as actual solution \\
just calculated:
---
yes or no
---
Student grade:
---
correct or incorrect
---
Question:
---
I'm building a solar power installation and I need help \ working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost \ me a flat $100k per year, and an additional $10 / square \ foot What is the total cost for the first year of operations \ as a function of the number of square feet.
---
Student's solution:
---
Let x be the size of the installation in square feet. Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 100x Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
---
Actual solution:
"""
response = get_completion(prompt)
print(response)
4 La Evolución de la Comprensión Contextual: El Mensaje del Sistema.
En marzo de 2023, OpenAI introdujo una característica revolucionaria en la API de sus modelos GPT 3.5 y GPT 4: el “mensaje del sistema” [18]. Antes de esta actualización, la API permitía que el modelo recibiera prompts y contexto a través de una matriz de mensajes categorizados como “user” (mensajes iniciados por el usuario) o “agent” (respuestas anteriores generadas por el modelo). El mensaje del sistema, sin embargo, está diseñado para ser el primer mensaje en esta matriz.
El mensaje del sistema cumple una función crítica: delinea el rol y los parámetros de comportamiento esperados del LLM. Esto permite una interacción más matizada y dirigida con el modelo, ya que proporciona al LLM pautas sobre cómo responder a los prompts subsiguientes.
La introducción del mensaje del sistema mejora significativamente la capacidad del usuario para guiar el comportamiento del modelo en tiempo real, sirviendo efectivamente como una extensión del concepto de entrenamiento ad hoc discutido anteriormente. Ofrece a los usuarios una herramienta más refinada para personalizar las respuestas del modelo, elevando así el nivel de interacción a una experiencia más dinámica y adaptada.
El siguiente fragmento muestra código Python que demuestra cómo usar la característica del mensaje del sistema para establecer el comportamiento del modelo como un mentor socrático.
import openai
...
# Define the system message to set the behavior of the model as a Socratic mentor
system_message = {
'role': 'system',
'content': 'You are a Socratic mentor. Engage in thoughtful dialogue,ask probing questions, and guide the user to deeper understanding.'
}
# Define a user message
user_message1 = {
'role': 'user',
'content': 'What is the meaning of life?'
}
# Define an agent message (a previous response from the model, if any)
agent_message1 = {
'role': 'agent',
'content': 'The meaning of life is a deeply philosophical question. What do you think it is?'
}
# Define another user message
user_message2 = {
'role': 'user',
'content': 'I think it is to find happiness.'
}
# Combine all messages into a list
messages = [system_message, user_message1, agent_message1, user_message2]
# Make an API call to GPT-4
response = openai.Completion.create(
model="gpt-4",
messages=messages
)
Este fragmento de código ilustra cómo el mensaje del sistema puede usarse para guiar el comportamiento del modelo, haciendo que la interacción sea más dinámica y adaptada a las necesidades individuales.
Referencias#
[12] Mikolov, T., et al. “Estimación eficiente de representaciones de palabras en espacio vectorial.” arXiv preprint arXiv:1301.3781 (2013).
[13] Vaswani, A., et al. “La atención es todo lo que necesitas.” Advances in neural information processing systems. 2017.
[14] API Backend Documentation." ChatPDF.com. Accedido el 25 de agosto de 2023. **https://www.chatpdf.com/docs/api/backend**.
[15] Devlin, J., et al. “BERT: Pre-entrenamiento de transformers bidireccionales profundos para la comprensión del lenguaje.” arXiv preprint arXiv:1810.04805 (2018).
[16] Howard, J., and Ruder, S. “Ajuste fino de modelo de lenguaje universal para clasificación de texto.” arXiv preprint arXiv:1801.06146 (2018).
[17] Suárez, Diego. “Cómo escribir instrucciones ‘System’ para la API de Chat GPT-4 de OpenAI.” Rootstrap Blog, 25 de abril de 2023. Blog de Rootstrap.
[18] OpenAI. “OpenAI Cookbook: Ejemplos y guías para usar la API de OpenAI.” Repositorio GitHub. Última modificación 22 de agosto de 2023. https://github.com/openai/openai-cookbook. Accedido el 23 de agosto de 2023